字节对齐
为什么需要字节对齐?
主要是解决硬件限制带来的问题,假设内存布局如下:

我想要一次性读取这四个字节的数据,在现代 X86 处理器上一条 MOV 指令就可以实现从 0x2 开始读四个字节的操作,然而有些处理器不支持这样操作,只支持从 0x0、0x4、0x8 等整倍数位置开始读取,不对齐的话就会导致处理器不得不访问两次内存,第一次读 0x0~0x3四个字节,第二次读 0x4~0x7 四个字节,然后再将两次读取的内容拼接起来。由于访问内存的操作翻了一倍,再加上多余的拼接操作,这会引起性能的严重下降。更有些处理器读取内存时如果地址不对齐则直接报错。
类似的,缓存也是重要因素,如果数据正好被分到两个缓存行里,即便缓存命中了也不能拿到全部数据,不得不再次访问缓存或内存,引起性能下降。
字节是怎么对齐的?
为了提高性能并保证移植性,C/C++ 编译器会帮我们做结构体字节对齐,关于具体的对齐规则,我认为知乎答主 pansz 的回答特别好:
- struct 内部每个成员按自身大小对齐
- struct 末尾紧贴着一个相同类型的 struct,也能够使下一个 struct 内成员对齐
举例:
struct my_data {
char a;
int s;
short c;
};
sizeof(struct my_data) 的结果是 12 个字节,此时内存布局如下:
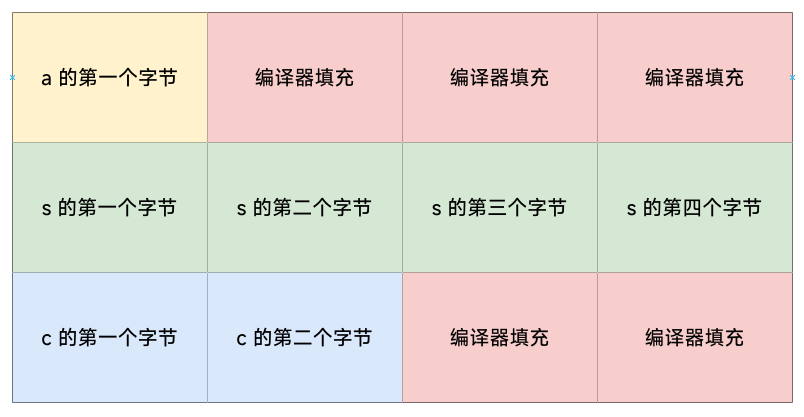
将字段 a 挪到字段 c 后面:
struct my_data {
int s;
short c;
char a;
};
sizeof(struct my_data) 的结果是 8 个字节,此时内存布局如下:

什么垃圾